Review “ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS”
ELECTRA:
PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
“좋은 backbone만 있으면 성능이 향상된다는 걸 증명”
INDEX
- INTRODUCTION
- METHOD
- EXPERIMENTS
- 3.1. EXPERIMENTAL SETUP
- 3.2. MODEL EXTENSIONS
- 3.3. SMALL MODELS
- 3.4. LARGE MODELS
- 3.5. EFFICIENCY ANALYSIS
- CONCLUSION
ABSTRACT
Replaced token detection
sample-efficient pre-training task
Instead of masking the input, our approach corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments demonstrate this new pre-training task is more efficient than MLM because the task is defined over all input tokens rather than just the small subset that was masked out.
ABSTRACT 설명
ABSTRACT에서는 sample-efficient pre-training task인 Replaced token detection에 대해 소개. Replaced token detection은 model이, 그럴듯하지만 실제로는 의미론적으로 생성된 대체물과 구별하는 방법을 학습하는 사전 훈련 작업. Replaced token detection 방법은 input을 masking하는 대신 small generator network에 의해 생성된 샘플로 일부 토큰을 대체한다. Masked language model(MLM)은 토큰의 원래 상태를 추측하는 방법으로 학습을 했지만 Replacted token detection 방법에서는 토큰의 원래 상태 추측까지는 generator가 하게 되지만 이후 discriminative model이 corrupted input에 들어있는 각 토큰이 generator sample에 의해 대체된 것인지, 아닌지 판단하는 방식으로 학습이 진행된다. 이 pre-training 방법은 maked된 subset에 대해서만 학습하는 것이 아니라 모든 input token에 대해 학습을 하기 때문에 MLM에 비해 더 효과적이라고 설명한다.
1. INTRODUCTION
We pre-train the network as a discriminator that predicts for every token whether it is an original or a replacement.
A key advantage of our discriminative task is that the model learns from ALL input tokens instead of just the small masked-out subset, making it more computationally efficient.
Our method is not adversarial in that the generator producing corrupted tokens is trained with maximum likelihood due to the difficulty of applying GANs to text

Our results indicate that the discriminative task of distinguishing real data from challenging negative samples is more compute-efficient and parameter-efficient than existing generative approaches for language representation learning.
INTRODUCTION 설명
BERT와 같은 MLM(masked language modeling)의 경우 전체 input에서 15%만 학습하기 때문에 높은 computing cost가 발생한다. ELECTRA에서는 일부 토큰을 small masked language model의 output에서 얻은 sample로 일부 토큰을 대체하여 input을 corrupt시킨다. 그리고 모든 토큰이 original인지, replacement인지 판단하는 discriminator 네트워크를 pre-train한다. ABSTRACT에서 설명된 것처럼 이러한 학습의 이점은 discriminative task로 인해 model이 모든 input 토큰으로부터 학습을 한다는 것.
Generator와 Discriminator를 사용한다는 부분에서 GAN과 비슷해보이지만 ELECTRA는 Adversarial하게 학습하지는 않는다. 논문에서는 Text에 GAN을 적용하기 어렵다고 설명하며 ‘Language GANs Falling Short (Caccia et al., 2018)’라는 논문을 소개하고 있다.
그래프는 다양한 크기의 ELECTRA 모델을 교육하고 다운 스트림 성능과 컴퓨팅 요구 사항을 평가한 것.
ELECTRA는 동일한 모델 크기, 데이터 및 컴퓨팅에서 BERT 및 XLNet과 같은 MLM 기반 방법보다 좋은 성능을 내고 있다. ELECTRA는 일반적인 language representation learning에 비해 compute-efficient하고 parameter-efficient하다고 할 수 있다.
2. METHOD
Our approach trains two neural networks, a generator G and a discriminator D.

METHOD 설명
ELECTRA에서는 generator G와 discriminator D, 두 네트워크를 학습시키게 된다. 각각은 Transformer와 같은 인코더로 되어 있고 여기서 Generator를 통해 변경된 값들을 sample이라고 표시하고 있다.
각각은 주로 입력 토큰 $x$ = [$x_1$, …, $x_n$]의 시퀀스를 컨텍스트화 된 벡터 표현 $h(x)$ = [$h_1$, …, $h_n$]의 시퀀스로 매핑하는 인코더 (예 : Transformer 네트워크)로 구성
Generator
For a given position $t$ (in our case only positions where $x_t$ = [MASK], the generator outputs a probability for generating a particular token $x_t$ with a softmax layer.
generator outputs a probability for generating a particular token $x_t$ with a softmax layer:
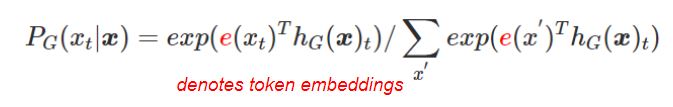
loss function
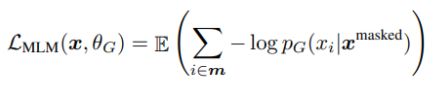
Generator 설명
Generator는 BERT와 같은 MLM을 수행하도록 학습한다. 아래 Softmax 함수를 통해 t번째 토큰의 원래 토큰 값이 무엇이었을지 예측하게 된다.
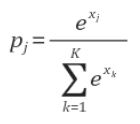
softmax 수식이 위처럼 생겼기 때문에 $exp(e(x_t)^Th_G(x)_t)$를 위 수식의 $e^{X_j}$라고 보면 된다.
Generator의 성능을 높이기 위한 Loss function은 MLE를 사용하고 있다. t번째 토큰의 Softmax 결과들을 모두 곱한 값이 최대가 되도록 하는 함수로 앞에 음수가 붙어있기 때문에 최댓값이 최솟값이 되며 이 최솟값을 구하는 경사하강법이 된다.
Discriminator
For a given position t, the discriminator predicts whether the token $x_t$ is “real,” i.e., that it comes from the data rather than the generator distribution, with a sigmoid output layer:
sigmoid output layer:
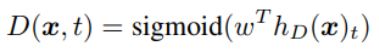
loss function
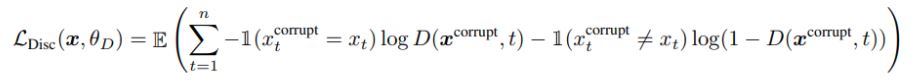
Discriminator 설명
Generator를 거쳐온 모든 토큰의 값이 real인지, 아닌지 sigmoid 함수를 통해 판단하게 된다. D의 결과는 이진 분류(real/fake)가 되고 아래 Loss function에서 D가 베르누이 분포가 된다. MLE를 통해 모수(x == x^)를 추정하는 식에서, (베르누이 확률밀도 함수에 대해) Log likelihood를 전개한 값이 Loss function(binomial likelihood)이 된다.
Combined loss
Although similar to the training objective of a GAN, there are several key differences.
First, if the generator happens to generate the correct token, that token is considered “real” instead of “fake”;
we found this formulation to moderately improve results on downstream tasks. More importantly, the generator is trained with maximum likelihood rather than begin trained adversarially to fool the discriminator.
Method 설명
LossMLM과 LossDiscriminator에 하이퍼파라미터 람다를 곱한 가중합을 최소화하는 것이 최종 손실함수가 된다.
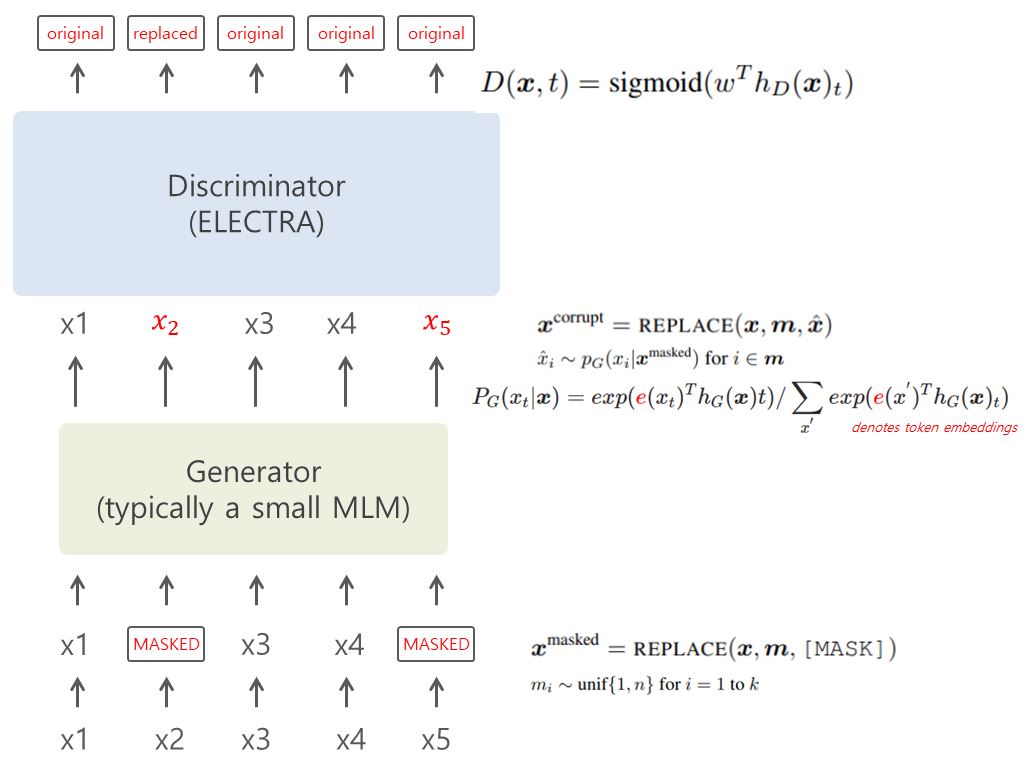
이미지에서 가장 아래 input token에서 15%를 랜덤으로 골라 mask를 하게 된다. mask된 값들은 $x^{masked}$처럼 표기한다. 그리고 이 mask된 값들을 generator에서 원래 token을 예측하는 softmax layer($P_G$ 함수)를 거쳐 output token으로 내보내고 generator에서 output된 값들은 discriminator에서 다시 input token이 되는데 이 중 generator에 의해 값이 변경된 토큰들을 corrupt라고 하며, mask된 x들을 표기한 것처럼 corrupt된 토큰들을 $x^{corrupt}$로 표시했다. 마지막 Discriminator에서 Sigmoid를 통해 input으로 들어온 각 토큰들이 real인지, 아닌지 판단해준다.
GAN과 비슷한 구조지만 적대적 훈련이 아니라 generator는 maximum likelihood(최대 가능도: 통계)로 훈련한다. 그리고 generator가 original과 동일한 sample을 출력하면 discriminator는 corrupt(generator에 의해 변경)된 값이더라도 해당 sample을 real(original)로 판단한다는 점에서 GAN과 차이가 있다. sampling step 때문에 discriminator의 loss를 generator의 생성 모델로 back-propagate 하는 것은 불가능하다고 설명한다. pre-training이 끝나면 generator는 버리고 discriminator(여기서는 ELECTRA 모델)만 fine-tune을 하게 된다.
3. EXPERIMENTS
3.1 EXPERIMENTAL SETUP
All of the pre-training and evaluation is on English data, although we think it would be interesting to apply our methods to multilingual data in the future.
Our model architecture and most hyperparameters are the same as BERT’s. For fine-tuning on GLUE, we add simple linear classifiers on top of ELECTRA. For SQuAD, we add the question-answering module from XLNet on top of ELECTRA..
EXPERIMENTAL SETUP 설명
ELECTRA는 GLUE와 SQuAD와 같은 평가 방법으로 평가했다고 나와있다. 그리고 ELECTRA 모델의 대부분 하이퍼 파라미터들은 BERT에서 사용된 것과 동일하며, 그 외에 GLUE, SQuAD에서 더 잘 동작하기 위해 ELECTRA 위에 linear classifier나, XLNet을 얹었다고 한다. 초기 설정과 관련된 자세한 내용은 Appendix에 설명되어 있다.
여기서 모든 pre-training 과정과 평가가 English data에 한정되어 있기 때문에 ELECTRA를 다른 언어에 적용하길 바란다고 적혀있는데 KoELECTRA가 적용한 예.
3.2 MODEL EXTENSIONS
Weight Sharing
We propose improving the efficiency of the pre-training by sharing weights between the generator and discriminator.
We found it to be more efficient to have a small generator, in which case we only share the embeddings (both the token and positional embeddings) of the generator and discriminator.
Weight tying strategies
500k steps.
- no weight tying : 83.6
- tying token embeddings: 84.3
- tying all weights: 84.4
Smaller Generators
We find that models work best with generators ¼ - ½ the size of the discriminator.
We speculate that having too strong of a generator may pose a too-challenging task for the discriminator, preventing it from learning as effectively.

Training Algorithms
We explore other training algorithms for ELECTRA, although these did not end up improving results.

MODEL EXTENSIONS 설명
ELECTRA에서는 성능을 높이기 위해 model에 몇 가지 확장을 했는데 이 실험에서는 BERT-Base와 동일한 모델 크기와 training data를 사용했다고 나와있다.
Weight Sharing - Discriminator와 Generator의 크기가 동일하면 모든 transformer의 weights를 공유할 있다. 처음에 model을 설계할 때 Discriminator와 Generator의 Weight을 공유하면 더 성능이 좋아지지 않을까 생각했지만 실제로 embedding weight만을 공유하고 Discriminator에 비해 더 작은 generator를 사용할 때 성능이 올라갔다고 설명한다. 임베딩 크기는 discriminator의 hidden state와 동일하게 사용했는데, generator에 linear layers를 추가했기 때문이다. BERT와 마찬자기로 생성 모델에서 input과 output의 토큰 embedding은 tie하여 학습했다. - 이미지는 Generator와 Discriminator 크기가 동일할 때 weight typing strategies에 대한 결과인데, tying을 전혀 안 한 것, token embedding만 tying 한 것, 모든 weight을 tying한 결과들 중 token embeddings을 tying할 때 성능이 가장 많이 올랐다. - Discriminator는 input 또는 Generator에 의해 샘플링 된 토큰만 업데이트하지만, Generator는 모든 토큰 embedding을 조밀하게 update한다. - all weight을 tying하는 게 가장 높지만 generator와 discriminator의 크기가 동일해야 한다는 단점에 비하면 크게 오르는 편이 아니다.
위 결과에 따라 이후 실험에서는 embeddings을 tie한 모델을 사용한다.
Smaller Generator - Discriminator에 비해 Generator의 크기가 ¼~½ 사이일 때 성능이 가장 좋다는 내용이다. Generator와 Discriminator의 크기가 같을 경우 ELECTRA를 훈련하는 것은 MLM만으로 훈련하는 것보다 step 당 계산 비용이 두 배가 된다. 또 Generator가 너무 뛰어날 경우 Discriminator에게 지나치게 도전적인 task를 부여해 오히려 학습 효율을 저하시킬 수 있다. - 그래프는 Discriminator에 따라 Generator의 크기가 1/4에서 1/2일 때 가장 성능이 좋다는 점을 나타낸다.
Training Algorithm
ELECTRA의 성능을 향상시키기 위해 Adversarial training(Training the generator adversarially as in a GAN, using reinforcement learning to accommodate the discrete operations of sampling from the generator), Two-Stage Training(During two-stage training, downstream task performance notably improves after the switch from the generative to the discriminative objective, but does not end up outscoring joint training.)을 시도해봤지만 그래프에 표시된 것처럼 앞에서부터 설명(maximum log likelihood 방법)한 ELECTRA에 비해 성능이 떨어진다는 사실을 알 수 있다.
3.2 SMALL MODELS
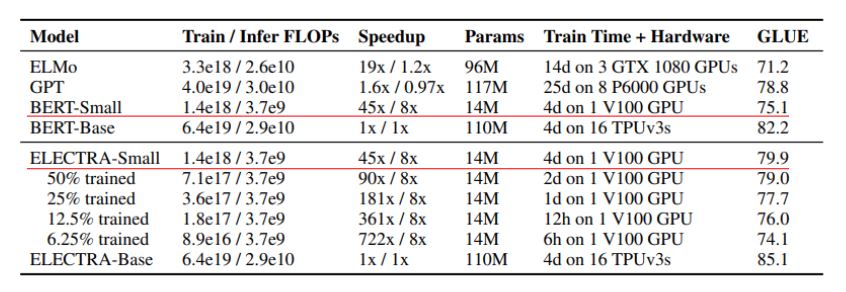
SMALL MODELS 설명
논문의 목표는 pre-training 효율을 향상시키는 것이다. 그래서 하나의 GPU에서 빠르게 학습할 수 있는 작은 모델들을 테스트했다. BERT-Base 하이퍼 파라미터에서 sequence length, batch size, hidden dimension size를 줄이고 더 작은 token embedding을 사용하는 BERT-Small이라는 모델을 150만 step동안 학습했다. 결과는 표에 나온 것처럼 ELECTRA-Small이 Params크기와 Train Time이 더 큰 다른 모델들에 비해 성능이 좋다는 사실을 확인할 수 있다.
Table3 Score이 들어간 경우, 앙상블과 같이 Score 값을 증가시키기 위해 몇 가지 trick을 사용했다고 하는데 Appendix를 통해 확인할 수 있다고 한다. ELECTRA는 ELECTRA-170만 학습. (RoBERTa는 500K 모델)
3.4 LARGE MODELS
We train big ELECTRA models to measure the effectiveness of the replaced token detection pre-training task at the large scale of current state-of-the-art pre-trained Transformers.
ELECTRA scores better than masked-language-modeling-based methods given the same compute resources.

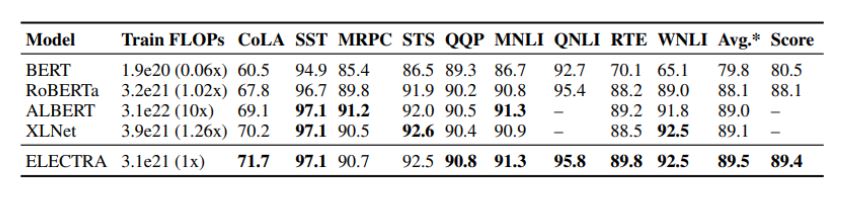
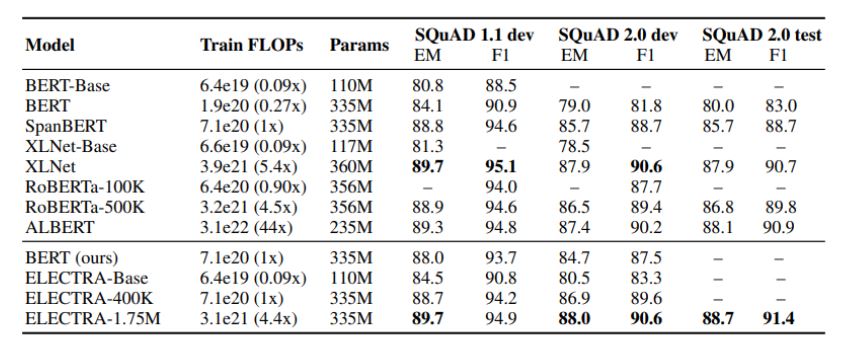
LARGE MODELS 설명
Replaced token detection이 pre-training task에서 큰 규모의 모델에서도 좋은 성능을 보인다는 내용이다. 동일한 자원이라면 ELECTRA는 MLM 기반 방법에 비해 더 좋은 성능을 낼 수 있다. (40만 step 학습은 RoBERTa의 1/4이고, 175만 step은 RoBERTa와 동일한 step의 학습)
3.5 EFFICIENCY ANALYSIS
- ELECTRA 15%: This model is identical to ELECTRA except the discriminator loss only comes from the 15% of the tokens that were masked out of the input.
- Replace MLM: This objective is the same as masked language modeling except instead of replacing masked-out tokens with [MASK], they are replaced with tokens form a generator model.
- All-Tokens MLM: Masked tokens are replaced with generator samples. Furthermore, the model predicts the identity of all tokens in the input, not just ones that were masked out.

We find that the gains from ELECTRA grow larger as the models get smaller. The small models are trained fully to convergence, showing that ELECTRA achieves higher downstream accuracy than BERT when fully trained. We speculate that ELECTRA is more parameter-efficient than BERT because it does not have to model the full distribution of possible tokens at each position, but we believe more analysis is needed to completely explain ELECTRA’s parameter efficiency.
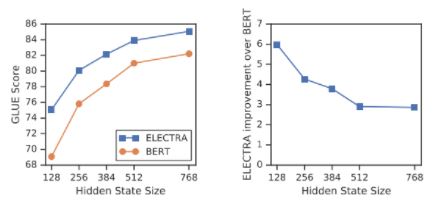
EFFICIENCY ANALYSIS 설명
MLM에서 일부 토큰만 학습하는 방법이 비효율적이다, 라고 설명했지만 실제 모든 토큰을 활용한 학습이 ELECTRA의 이점이 되는지 명확하지 않을 수 있다고 생각할 수 있기 때문에 ELECTRA의 어떤 점이 MLM에 비해 더 좋은 성능을 낼 수 있게 하는 것인지 명확하게 하기 위해 BERT와 ELECTRA.사이의 차이점을 하나씩 제거하는 방식으로 테스트를 수행했다.
- ELECTRA-15%: BERT처럼 masked된 input 토큰만으로 discriminator의 loss를 계산하는 방법.
- Replace MLM: MASK를 사용하지 않고 Generator로 생성된 토큰을 사용하는 방법. [MASK]라는 토큰을 모델에게 pre-train시키고 fine-tuning에서는 사용하지 않는 방법으로 인한 mismatch(불일치)를 없앴을 때 성능 차이가 있는 지 확인할 수 있는 실험 방법이다.
- All-Tokens MLM: BERT와 ELECTRA를 합친 것으로 mask된 토큰이 아닌 모든 토큰을 예측하는 모델이다.
결과 표를 보시면 ELECTRA 다음으로 All-Tokens MLM, Replace MLM 성능이 좋다. 이 결과는 ELECTRA의 성능은 모든 토큰에서 배운다는 점이 가장 크게 작용하고, 추가로 MASK가 아닌 토큰을 학습한다는 점에서 pre-train fine-tune mismatch의 완화가 가능하다는 점이 작용한다는 것을 알 수 있다.
그래프를 보면 모델이 작을 수록 ELECTRA에서 얻는 것이 증가한다는 사실을 알 수 있다. 가운데 Hidden State Size가 커지면 커질수록 BERT와의 차이가 줄어드는 것을 볼 수 있다. 토큰의 가능한 모든 위치의 분포를 모델링하지 않아도 되기 때문에 BERT에 비해 parameter-efficient하다고 할 수 있지만 ELECTRA의 parameter efficiency와 관련해서 완벽하게 설명하기 위해서는 분석이 더 필요하다고 설명한다.
CONCLUSION
We have proposed replaced token detection, a new self-supervised task for language representation learning. The key idea is training a text encoder to distinguish input tokens from high-quality negative samples produced by an small generator network. Compared to masked language modeling, our pre-training objective is more compute-efficient and results in better performance on downstream tasks. It works well even when using relatively small amounts of compute, which we hope will make developing and applying pre-trained text encoders more accessible to researchers and practitioners with less access to computing resources. We also hope more future work on NLP pre-training will consider efficiency as well as absolute performance, and follow our effort in reporting compute usage and parameter counts along with evaluation metrics.
CONCLUSION 설명
논문에서는 language representation learning을 위한 새로운 Self-supervised learning task인 Replaced Token Detection을 제안하고 있다. 핵심은 text encoder가 small generator network가 만들어낸 고품질의 negative sample을 사용해 만들어낸 sample들의 input 토큰 구분하도록 학습시키는 것. MLM과 비교해, 논문의 pre-training objective 계산이 효율적이며 downstream task에서 더 좋은 성능을 낼 수 있다. 상대적으로 적은 양의 컴퓨팅을 사용하는 경우에도 잘 작동하므로 컴퓨팅 리소스에 대한 엑세스 권한이 적은 연구원과 실무자가 pre-trained text encoder를 개발하고 적용할 수 있기를 바란다는 결론.